
Code LLM全景综述,从LLM到Agent,全文长303页,北航阿里字节等12家机构联合撰写|最新
Code LLM全景综述,从LLM到Agent,全文长303页,北航阿里字节等12家机构联合撰写|最新这篇论文由北京航空航天大学、阿里巴巴、字节跳动、上海人工智能实验室等几十家顶尖机构联合撰写,全文长达303页,是对当前“代码大模型(Code LLMs)”领域最详尽的百科全书式指南。
来自主题: AI技术研报
12105 点击 2025-12-05 09:24
 搜索
搜索
这篇论文由北京航空航天大学、阿里巴巴、字节跳动、上海人工智能实验室等几十家顶尖机构联合撰写,全文长达303页,是对当前“代码大模型(Code LLMs)”领域最详尽的百科全书式指南。
如今 LLM 的语言理解与生成能力已展现出惊人的广泛适用性,但随着 LLM 的发展,一个事实越发凸显:仅靠语言,仍不足以支撑真正的智能。

在 LLM 优化领域,有两个响亮的名字:Adam(及其变体 AdamW)和 Muon。
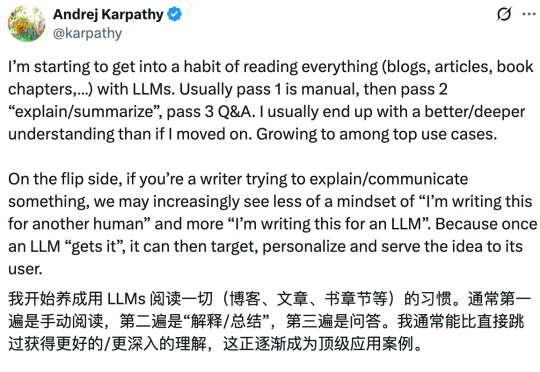
前 OpenAI 联合创始人、特斯拉 AI 总监 Andrej Karpathy 也一样。他在前几天发推,说自己「开始养成用 LLM 阅读一切的习惯」。Karpathy 在周六用氛围编程做了个新的项目,让四个最新的大模型组成一个 LLM 议会,给他做智囊团。
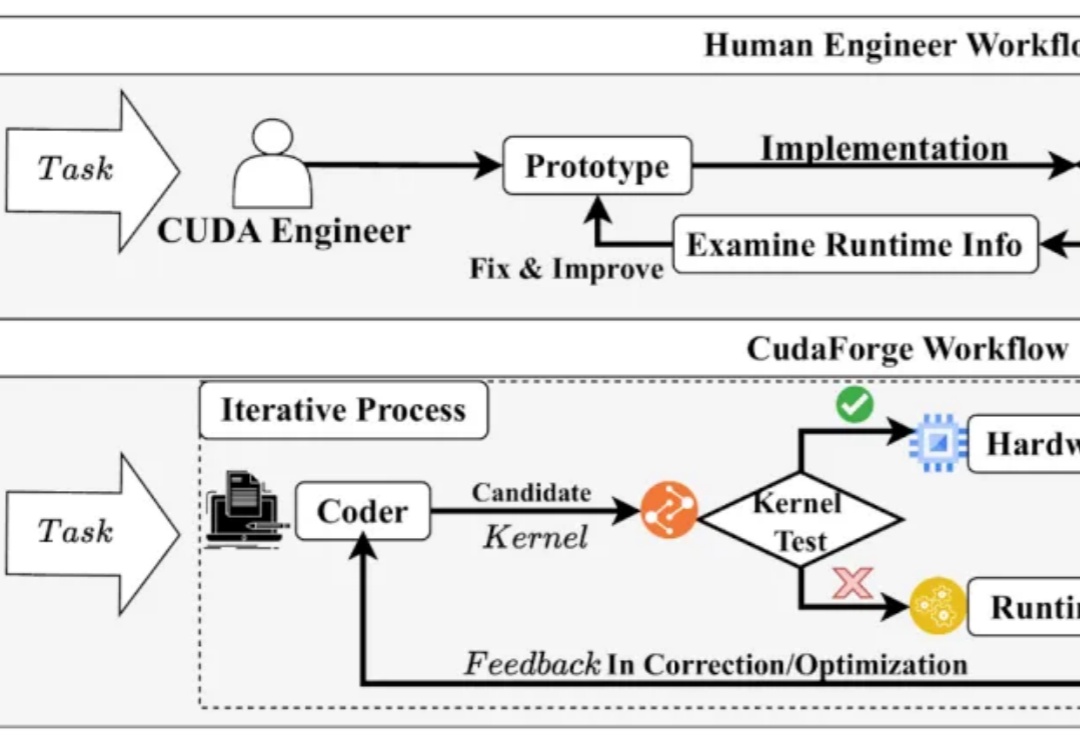
CUDA 代码的性能对于当今的模型训练与推理至关重要,然而手动编写优化 CUDA Kernel 需要很高的知识门槛和时间成本。与此同时,近年来 LLM 在 Code 领域获得了诸多成功。
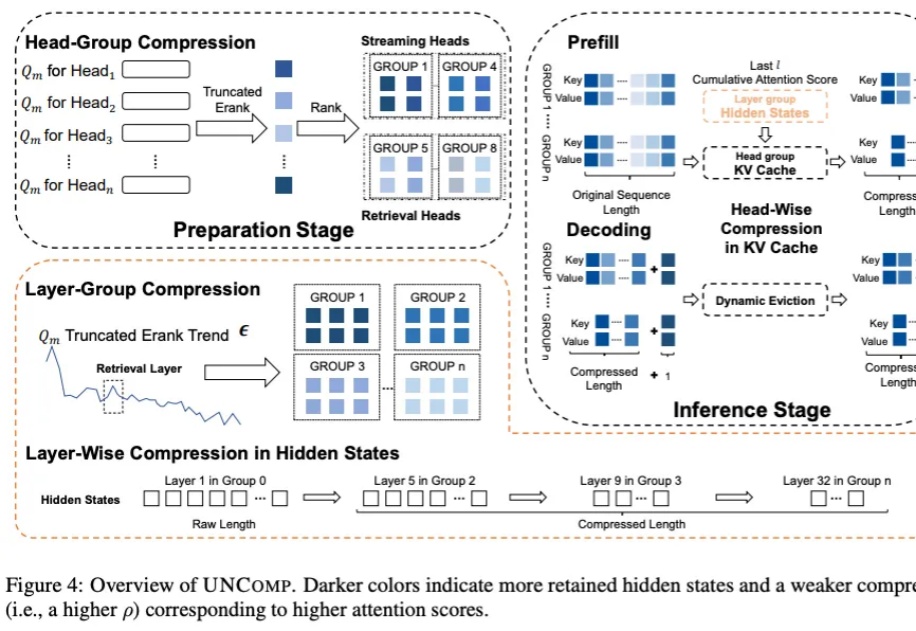
我们都知道 LLM 中存在结构化稀疏性,但其底层机制一直缺乏统一的理论解释。为什么模型越深,稀疏性越明显?为什么会出现所谓的「检索头」和「检索层」?
近期,HuggingFace 发布的超过 200 页的超长技术博客,系统性地分享训练先进 LLM 的端到端经验。

LLM Agent 正以前所未有的速度发展,从网页浏览、软件开发到具身控制,其强大的自主能力令人瞩目。然而,繁荣的背后也带来了研究的「碎片化」和能力的「天花板」:多数 Agent 在可靠规划、长期记忆、海量工具管理和多智能体协调等方面仍显稚嫩,整个领域仿佛一片广袤却缺乏地图的丛林。

众所周知,大型语言模型(LLM)的根本运作方式是预测下一个 token(词元),能够保证生成的连贯性和逻辑性,但这既是 LLM 强大能力的「灵魂」所在,也是其枷锁,将导致高昂的计算成本和响应延迟。 可

著名数学家陶哲轩发论文了,除了陶大神,论文作者还包括 Google DeepMind 高级研究工程师 BOGDAN GEORGIEV 等人。论文展示了 AlphaEvolve 如何作为一种工具,自主发现新的数学构造,并推动人们对长期未解数学难题的理解。AlphaEvolve 是谷歌在今年 5 月发布的一项研究,一个由 LLMs 驱动的革命性进化编码智能体。